![]()
Quantum Circuit Born Machine
Yao is designed with variational quantum circuits in mind, and this tutorial will introduce how to use Yao for this kind of task by implementing a quantum circuit born machine described in Jin-Guo Liu, Lei Wang (2018)
let's use the packages first
using Yao, LinearAlgebra, PlotsTraining Target
In this tutorial, we will ask the variational circuit to learn the most basic distribution: a guassian distribution. It is defined as follows:
\[f(x \left| \mu, \sigma^2\right) = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]
We implement it as gaussian_pdf:
function gaussian_pdf(x, μ::Real, σ::Real)
pl = @. 1 / sqrt(2pi * σ^2) * exp(-(x - μ)^2 / (2 * σ^2))
pl / sum(pl)
end
pg = gaussian_pdf(1:1<<6, 1<<5-0.5, 1<<4);We can plot the distribution, it looks like
Plots.plot(pg)Create the Circuit
A quantum circuit born machine looks like the following:
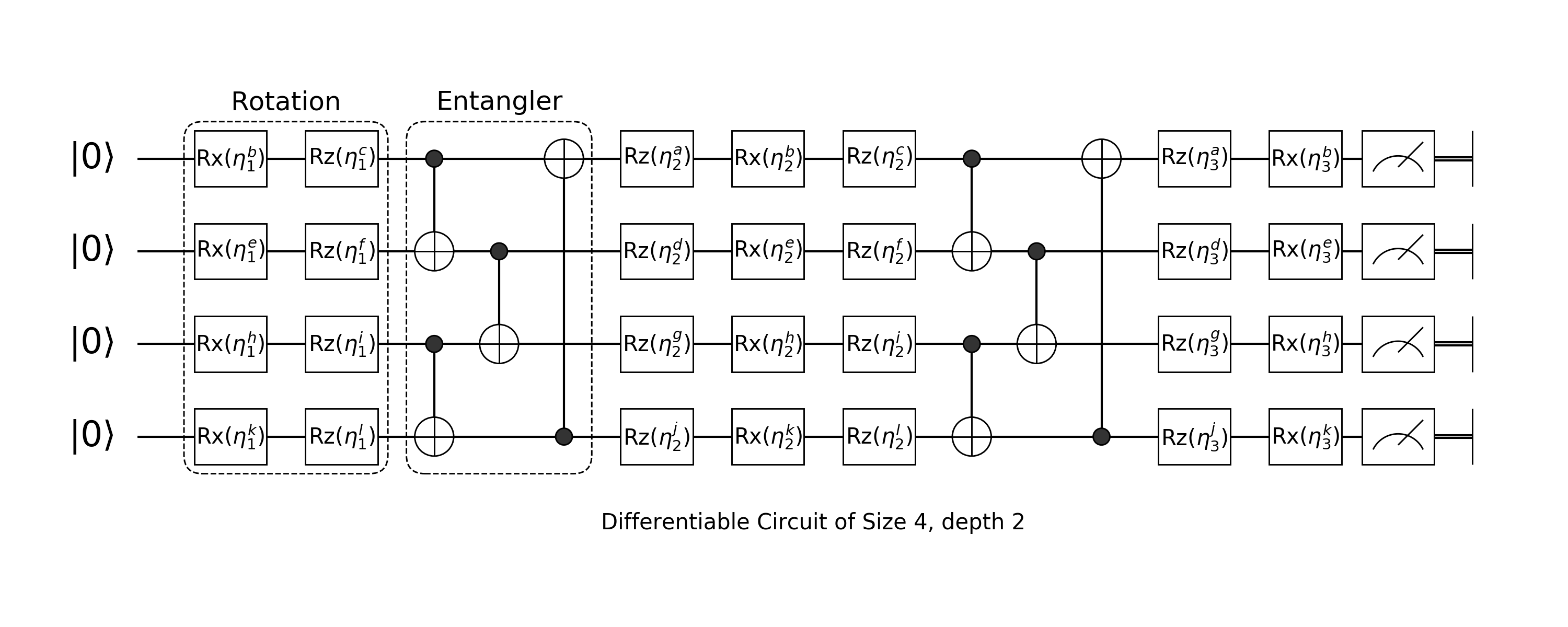
It is composited by two different layers: rotation layer and entangler layer.
Rotation Layer
Arbitrary rotation is built with Rotation Gate on Z, X, Z axis with parameters.
\[Rz(\theta) \cdot Rx(\theta) \cdot Rz(\theta)\]
Since our input will be a $|0\dots 0\rangle$ state. The first layer of arbitrary rotation can just use $Rx(\theta) \cdot Rz(\theta)$ and the last layer of arbitrary rotation could just use $Rz(\theta)\cdot Rx(\theta)$
In 幺, every Hilbert operator is a block type, this ncludes all quantum gates and quantum oracles. In general, operators appears in a quantum circuit can be divided into Composite Blocks and Primitive Blocks.
We follow the low abstraction principle and thus each block represents a certain approach of calculation. The simplest Composite Block is a Chain Block, which chains other blocks (oracles) with the same number of qubits together. It is just a simple mathematical composition of operators with same size. e.g.
\[\text{chain(X, Y, Z)} \iff X \cdot Y \cdot Z\]
We can construct an arbitrary rotation block by chain $Rz$, $Rx$, $Rz$ together.
chain(Rz(0.0), Rx(0.0), Rz(0.0))nqubits: 1
chain
├─ rot(Z, 0.0)
├─ rot(X, 0.0)
└─ rot(Z, 0.0)Rx, Rz will construct new rotation gate, which are just shorthands for rot(X, 0.0), etc.
Then let's chain them up
layer(nbit::Int, x::Symbol) = layer(nbit, Val(x))
layer(nbit::Int, ::Val{:first}) = chain(nbit, put(i=>chain(Rx(0), Rz(0))) for i = 1:nbit);We do not need to feed the first n parameter into put here. All factory methods can be lazy evaluate the first arguements, which is the number of qubits. It will return a lambda function that requires a single interger input. The instance of desired block will only be constructed until all the information is filled. When you filled all the information in somewhere of the declaration, 幺 will be able to infer the others. We will now define the rest of rotation layers
layer(nbit::Int, ::Val{:last}) = chain(nbit, put(i=>chain(Rz(0), Rx(0))) for i = 1:nbit)
layer(nbit::Int, ::Val{:mid}) = chain(nbit, put(i=>chain(Rz(0), Rx(0), Rz(0))) for i = 1:nbit);Entangler
Another component of quantum circuit born machine are several CNOT operators applied on different qubits.
entangler(pairs) = chain(control(ctrl, target=>X) for (ctrl, target) in pairs);We can then define such a born machine
function build_circuit(n, nlayers, pairs)
circuit = chain(n)
push!(circuit, layer(n, :first))
for i in 2:nlayers
push!(circuit, cache(entangler(pairs)))
push!(circuit, layer(n, :mid))
end
push!(circuit, cache(entangler(pairs)))
push!(circuit, layer(n, :last))
return circuit
endbuild_circuit (generic function with 1 method)We use the method cache here to tag the entangler block that it should be cached after its first run, because it is actually a constant oracle. Let's see what will be constructed
build_circuit(4, 1, [1=>2, 2=>3, 3=>4])nqubits: 4
chain
├─ chain
│ ├─ put on (1)
│ │ └─ chain
│ │ ├─ rot(X, 0.0)
│ │ └─ rot(Z, 0.0)
│ ├─ put on (2)
│ │ └─ chain
│ │ ├─ rot(X, 0.0)
│ │ └─ rot(Z, 0.0)
│ ├─ put on (3)
│ │ └─ chain
│ │ ├─ rot(X, 0.0)
│ │ └─ rot(Z, 0.0)
│ └─ put on (4)
│ └─ chain
│ ├─ rot(X, 0.0)
│ └─ rot(Z, 0.0)
├─ [cached] chain
│ ├─ control(1)
│ │ └─ (2,) X
│ ├─ control(2)
│ │ └─ (3,) X
│ └─ control(3)
│ └─ (4,) X
└─ chain
├─ put on (1)
│ └─ chain
│ ├─ rot(Z, 0.0)
│ └─ rot(X, 0.0)
├─ put on (2)
│ └─ chain
│ ├─ rot(Z, 0.0)
│ └─ rot(X, 0.0)
├─ put on (3)
│ └─ chain
│ ├─ rot(Z, 0.0)
│ └─ rot(X, 0.0)
└─ put on (4)
└─ chain
├─ rot(Z, 0.0)
└─ rot(X, 0.0)
MMD Loss & Gradients
The MMD loss is describe below:
\[\begin{aligned} \mathcal{L} &= \left| \sum_{x} p \theta(x) \phi(x) - \sum_{x} \pi(x) \phi(x) \right|^2\\ &= \langle K(x, y) \rangle_{x \sim p_{\theta}, y\sim p_{\theta}} - 2 \langle K(x, y) \rangle_{x\sim p_{\theta}, y\sim \pi} + \langle K(x, y) \rangle_{x\sim\pi, y\sim\pi} \end{aligned}\]
We will use a squared exponential kernel here.
struct RBFKernel
σ::Float64
m::Matrix{Float64}
end
function RBFKernel(σ::Float64, space)
dx2 = (space .- space').^2
return RBFKernel(σ, exp.(-1/2σ * dx2))
end
kexpect(κ::RBFKernel, x, y) = x' * κ.m * ykexpect (generic function with 1 method)There are two different way to define the loss:
In simulation we can use the probability distribution of the state directly
get_prob(qcbm) = probs(zero_state(nqubits(qcbm)) |> qcbm)
function loss(κ, c, target)
p = get_prob(c) - target
return kexpect(κ, p, p)
endloss (generic function with 1 method)Or if you want to simulate the whole process with measurement (which is entirely physical), you should define the loss with measurement results, for convenience we directly use the simulated results as our loss
Gradients
the gradient of MMD loss is
\[\begin{aligned} \frac{\partial \mathcal{L}}{\partial \theta^i_l} &= \langle K(x, y) \rangle_{x\sim p_{\theta^+}, y\sim p_{\theta}} - \langle K(x, y) \rangle_{x\sim p_{\theta}^-, y\sim p_{\theta}}\\ &- \langle K(x, y) \rangle _{x\sim p_{\theta^+}, y\sim\pi} + \langle K(x, y) \rangle_{x\sim p_{\theta^-}, y\sim\pi} \end{aligned}\]
which can be implemented as
function gradient(qcbm, κ, ptrain)
n = nqubits(qcbm)
prob = get_prob(qcbm)
grad = zeros(Float64, nparameters(qcbm))
count = 1
for k in 1:2:length(qcbm), each_line in qcbm[k], gate in content(each_line)
dispatch!(+, gate, π/2)
prob_pos = probs(zero_state(n) |> qcbm)
dispatch!(-, gate, π)
prob_neg = probs(zero_state(n) |> qcbm)
dispatch!(+, gate, π/2) # set back
grad_pos = kexpect(κ, prob, prob_pos) - kexpect(κ, prob, prob_neg)
grad_neg = kexpect(κ, ptrain, prob_pos) - kexpect(κ, ptrain, prob_neg)
grad[count] = grad_pos - grad_neg
count += 1
end
return grad
endgradient (generic function with 1 method)Now let's setup the training
import Optimisers
qcbm = build_circuit(6, 10, [1=>2, 3=>4, 5=>6, 2=>3, 4=>5, 6=>1])
dispatch!(qcbm, :random) # initialize the parameters
κ = RBFKernel(0.25, 0:2^6-1)
pg = gaussian_pdf(1:1<<6, 1<<5-0.5, 1<<4);
opt = Optimisers.setup(Optimisers.ADAM(0.01), parameters(qcbm));
function train(qcbm, κ, opt, target)
history = Float64[]
for _ in 1:100
push!(history, loss(κ, qcbm, target))
ps = parameters(qcbm)
Optimisers.update!(opt, ps, gradient(qcbm, κ, target))
dispatch!(qcbm, ps)
end
return history
end
history = train(qcbm, κ, opt, pg)
trained_pg = probs(zero_state(nqubits(qcbm)) |> qcbm)64-element Vector{Float64}:
0.004325753672883842
0.004809288981388637
0.005343955943160174
0.0059828445868545
0.006650487515518758
0.0073251471759878005
0.00809305850499482
0.008968166588369781
0.009732093153941124
0.010446645701074059
0.011522445767397187
0.012407815149194899
0.013434657542493789
0.014379272056723999
0.015324609960667712
0.016391572954458304
0.01735589115479334
0.018226199801256095
0.01929971037644516
0.020212182079373274
0.021089874415171805
0.021840354205719333
0.02260766939471365
0.023473131828612066
0.024216602652870296
0.024572590122921244
0.025162038098588704
0.02553717035326974
0.025773231427538127
0.02604300748164771
0.02613471204403263
0.026112603622769456
0.026055378672243567
0.0259165242086804
0.025404531278722883
0.02510779147195523
0.02453817392540539
0.024071110746203144
0.023351760532931615
0.022750868945474238
0.021931569688167257
0.021095492026975547
0.020235003469557398
0.01928178169126925
0.01839261032700247
0.017336393679358762
0.01633960256616451
0.015465586040344523
0.014440801880786395
0.013377994020307269
0.01239281374410882
0.011440952590457156
0.01051654277221679
0.00969931795169636
0.008793921607602994
0.00811633155092302
0.007303456056812086
0.0065625405831562355
0.005900856986801528
0.005357349247928561
0.00473896986731482
0.004277824206117947
0.0037741256331175997
0.0032372377153637518The history of training looks like below
title!("training history")
xlabel!("steps"); ylabel!("loss")
Plots.plot(history)And let's check what we got
fig2 = Plots.plot(1:1<<6, trained_pg; label="trained")
Plots.plot!(fig2, 1:1<<6, pg; label="target")
title!("distribution")
xlabel!("x"); ylabel!("p")So within 50 steps, we got a pretty close estimation of our target distribution!
This page was generated using Literate.jl.